

Os sons da fala das línguas humanas naturais produzem-se usando o ar disponível nos pulmões e ao longo do trato vocal. A fonação (vibração das cordas vocais) gera-se ao criar uma diferença de pressão entre o ar nos pulmões e o ar no trato vocal, que é a parte do aparelho respiratório entre as cordas vocais e os lábios (ou as narinas). A diferença de pressão necessária para a fonação cria-se fechando a glote de forma a impedir a passagem do ar dos pulmões para o trato vocal (i.e. as cavidades supraglotais, ou as cavidades acima da glote) enquanto a ação conjunta do diafragma e dos músculos intercostais, abdominais, dorsais, etc., fazem reduzir o volume da caixa torácica, o que leva automaticamente a um aumento da pressão subglotal (pressão do ar nos pulmões). A queda de pressão que assim se cria entre a pressão subglotal e a pressão supraglotal gera forças que tendem a abrir a glote. O que se passa com o ar na região da glote é semelhante ao que acontece com as diferenças de níveis da água no açude do Rio Liz. A zona em que o nível da água é mais alta corresponde aos pulmões e a zona depois do açude seria equivalente às cavidades supraglotais. Porém, no caso do Rio Liz o açude é construído de forma a não ceder às força que se geram com a diferença de níveis, o que é equivalente a manter a glote fechada quando fazemos esforço e precisamos de usar a caixa torácica como suporte firme dos músculos abdominais. Para criar fonação, a tensão muscular das cordas vocais tem que ser ajustada com precisão de forma a que as forças geradas pela diferença de pressões excedam ligeiramente as da tensão muscular e possam de facto forçar a abertura da glote. Quando essa abertura começa a permitir que o ar passe através da glote, é o próprio escoamento rápido do ar que gera uma força de sucção que ajuda a tensão muscular a fechar de novo a glote. Mas quando a força de sucção desaparece porque o fluxo de ar é interrompido, “vence” de novo a pressão pulmonar e a glote é forçada a abrir e o ciclo continua a repetir-se desde que essas condições de diferença de pressão e tensão muscular se mantenham.
Este processo de vibração pode ilustrar-se usando duas colheres “de costas uma para a outra” e deixando passar um fluxo de água entre elas. Regulando a tensão com que se seguram as colheres para que se ajuste à pressão que cria o fluxo de água, o sistema entra em vibração devido aos mesmos princípios físicos que levam à vibração das cordas vocais.
Do ponto de vista acústico, o trato vocal comporta-se como um tubo que vai da glote aos lábios quando a passagem para a cavidade nasal está bloqueada pelo velum. Este modelo acústico é naturalmente simplificado porque na realidade a forma e o diâmetro do trato vocal não é constante ao longo do trato vocal, nem mesmo para as posições articulatórias mais “simples”. Apesar disso, o modelo acústico é uma aproximação útil para o cálculo das frequências de ressonância do trato vocal com precisão aceitável. Acima de tudo, o modelo acústico permite compreender aspetos fundamentais do processo de produção de sons da fala que não só explicar a natureza das observações e relações entre os sons da fala que se registam e medem em análises fonéticas, mas também predizer as consequências de articulações atípicas, como as que surgem em certas patologias da fala. Análises acústico-articulatórias são muito complexas e requerem conhecimentos profundos em várias disciplinas mas as simplificações que o modelo acústico oferece são extremamente valiosas para uma orientação na matéria. E, por falar em complicações, o tubo acústico que representa o trato vocal oral complica-se imediatamente ao tentar modelar um som nasalado. Neste caso, é necessário adicionar ao tubo inicial um novo tubo que representa as fossas nasais como uma ramificação lateral do tubo oral que surge quando o velum não bloqueia a passagem para a cavidade nasal.
A figura seguinte mostra três imagens da minha cabeça obtidas com a câmara de ressonância magnética (MRI) do Stockholm University Brain Imaging Centre (www.su.se/subic). À primeira vista estas imagens fazem lembrar radiografias, mas são fundamentalmente diferentes. Radiografias são “sombras” de duas dimensões que se geram quando se “iluminam” com raios-X estruturas com diferentes “transparências” à radiação; as “imagens” obtidas com MRI são volumes, estruturas a três dimensões, em que é possível navegar. Os traços azuis que se vêm na figura representam os diferentes planos que cortam o volume que representa a minha cabeça. A imagem do lado direito representa uma fatia no plano sagital (perfil) onde se vê distintamente o meu trato vocal e o velum relaxado, que não bloqueia a passagem para a cavidade nasal. Na imagem superior esquerda vemos um corte segundo o plano vertical indicado no corte sagital e a imagem inferior esquerda mostra um corte horizontal mais ou menos ao nível dos olhos. Com o programa de visualização que utilizei para criar estas imagens posso alterar a posição dos planos indicados pelas linhas azuis e navegar ao longo das três dimensões da imagem.
A imagem com mais interesse de momento é a da direita, que mostra o corte sagital ao meio da cabeça. O tubo acústico a que temos referido começa neste caso um pouco abaixo da base da figura porque esta imagem não inclui as cordas vocais. Se usarmos as vertebras da coluna vertebral com indicação da posição das minhas cordas vocais, a glote iria estar cerca de mais uma vértebra abaixo do que se vê na figura. O tubo acústico equivalente começa na glote e segue o contorno da língua até chegar aos lábios. Como se vê também, eu estou com a lâmina da língua a fazer contacto com os incisivos superiores, o que no modelo acústico corresponde a um estrangulamento do tubo nessa zona. Com essa articulação, o som oral que eu produziria seria mais ou menos um [d] ou um [t], dependendo de as cordas vocais vibrarem ou não enquanto a língua faz contacto com os incisivos superiores. Mas neste caso o velum não bloqueia a passagem do som para o trato nasal (que parece fechado porque este corte sagital está a apanhar o septo que separa as fossas nasais) e o som resultante seria então, aproximadamente, um [n].
Na realidade, eu não estava de facto a dizer som nenhum nesta altura. Estava simplesmente deitado, de costas, e a respirar pelo nariz enquanto a câmara de ressonância magnética fazia a análise do volume da minha cabeça.
A figura seguinte mostra o modelo acústico correspondente à posição articulatória de um [d] – a articulação que se vê na figura da direita, mas supondo que o velum estava levantado para não permitir a ramificação para a cavidade nasal.
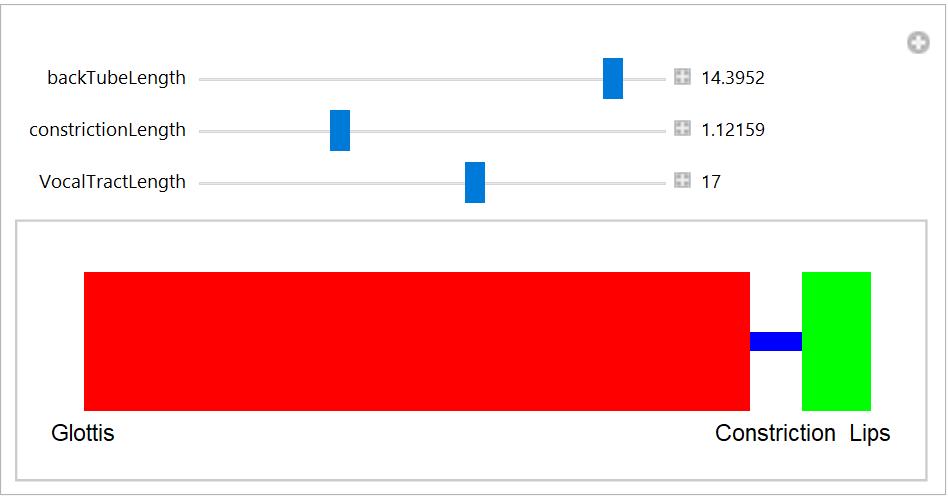
Se o corpo da língua estivesse a fazer contacto com o próprio velum (levantado), o modelo acústico equivalente seria o que mostra a próxima figura.
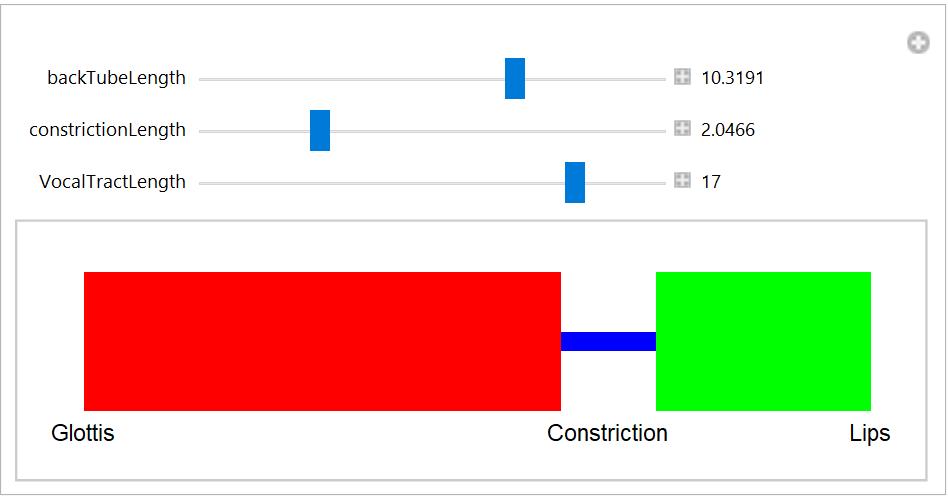
Como se vê, o comprimento do trato vocal é sempre o mesmo (aproximadamente, não considerando a possível extensão dos lábios e as consequências acústicas da área da abertura dos lábios – eu disse que era complexo…) e por isso quando o comprimento do tubo recuado (da glote ao ponto de contacto da língua com o velum, por exemplo) diminui, aumenta automaticamente o comprimento do tubo dianteiro e vice-versa. Como as frequências de ressonância de um tubo ficam mais altas à medida que o comprimento do tubo diminui, e vice-versa, mais baixas quando a dimensão longitudinal aumenta, articular consoantes com diferentes pontos de articulação ao longo do trato vocal leva a que o tubo recuado e o anterior “se revezem” na ordem por que aparecem as frequências de ressonância das diversas articulações. Assim, quando o ponto de articulação é avançado, o tubo recuado é mais longo e é por isso o responsável pelas frequências mais baixas. Inversamente, quando o ponto de articulação fica mais próximo da glote, é o tubo dianteiro que gera as frequências mais baixas. A figura seguinte mostra como as frequências de ressonância dos dois tubos variam com a posição articulatória em relação à glote.
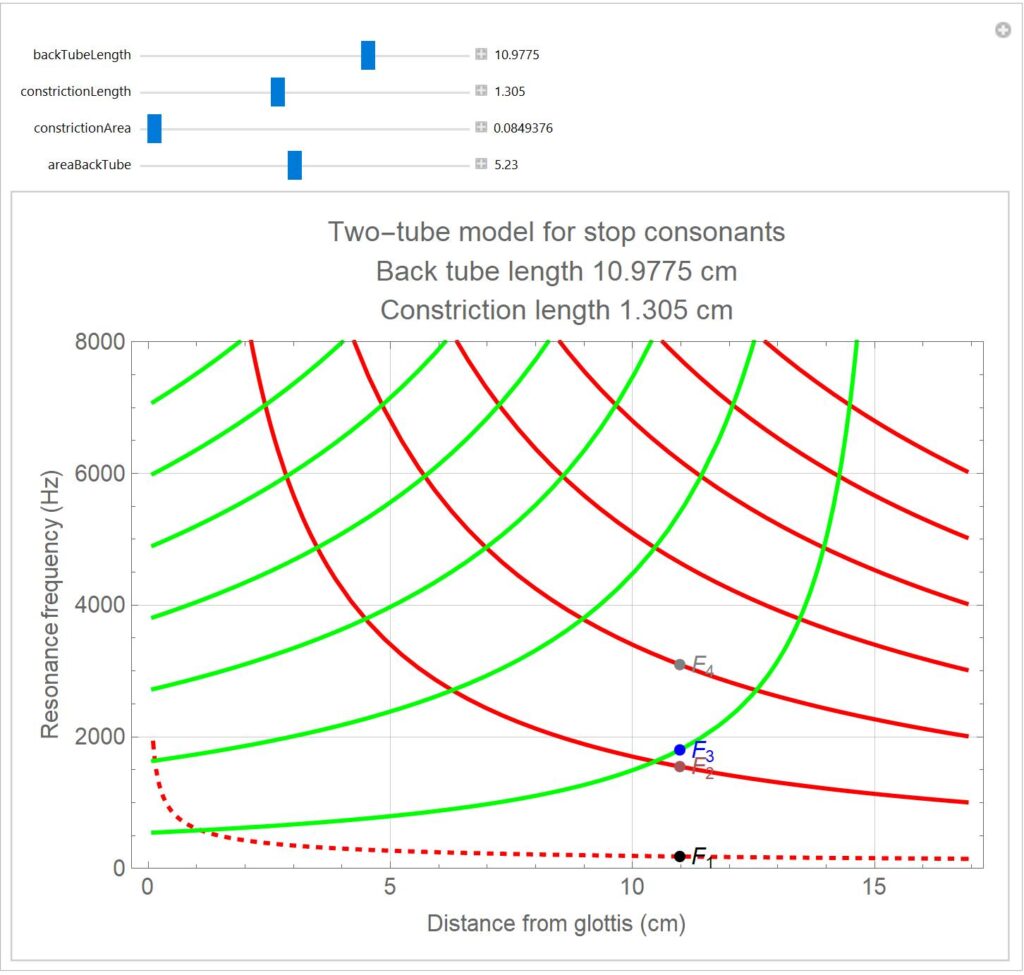
Na figura pode ver-se que as frequências de ressonância finais se mantêm dentro de gamas típicas porque cada vez que um tubo, por si, gera frequências fora dessa gama, é substituído pelas frequências que o outro produz. A figura mostra também que as frequências de ressonância do modelo não variam uniformemente quando a posição articulatória se altera em pequenos passos iguais entre a glote e os lábios. Quando o ponto de articulação faz com que algumas das frequências de ressonâncias dos tubos sejam iguais, avançar ou recuar a posição articulatória não altera muito o resultado final. São regiões de estabilidade acústico-articulatória correspondentes às distâncias para as quais se cruzam as curvas de ressonância que se vêm na figura.
Quando as constrições ao longo do trato vocal não são completas de forma a dividi-lo em dois tubos, o resultado são vogais com qualidades sonoras que dependem da posição da constrição parcial. O vídeo que se segue mostra, com um modelo físico, as consequências acústicas dessas constrições não completas características das vogais.
Voltando à imagem do corte sagital, se em vez de um falante adulto tivéssemos analisado um bebé recém-nascido, a posição da glote seria muito mais elevada, ao nível da terceira vértebra. Durante os primeiros meses de vida, o bebé tem uma faringe muito curta e a raiz da língua estaria muito mais alta do que o que se vê num adulto. A posição da glote, medida em relação às vertebras, altera-se rapidamente durante os primeiros meses de vida, como se vê no gráfico junto, mas inicialmente o bebé não tem praticamente faringe embora muitos dos sons da lalação sejam percebidos exatamente como faringais.
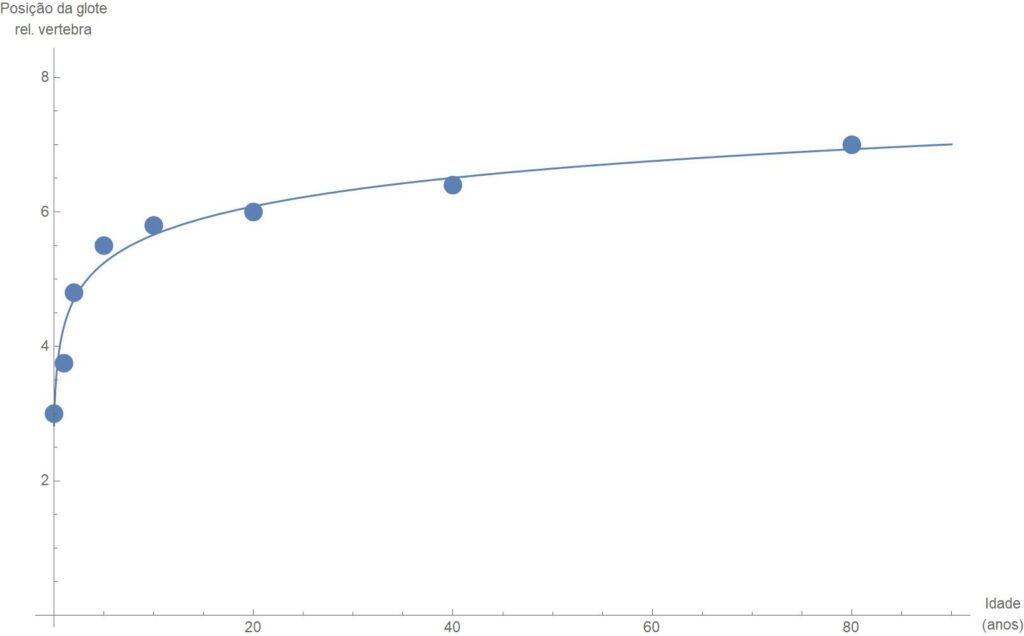
Esse aparente paradoxo explica-se considerando que a articulação que o bebé realmente usa é o que anatomicamente se chamaria velar. A língua do bebé faz contacto com o velum, como se fosse produzir um [g]. Porém, a posição relativa desse contacto em relação à glote corresponde a uma constrição muito recuada no tal modelo articulatório do trato vocal. Como adultos, interpretamos o som que o bebé produz com uma constrição velar em termos da articulação que precisamos de fazer para imitar o som do bebé. Como em acústica, o que determina as frequências de ressonância é a posição relativa da constrição no tubo acústico, somos levados a interpretar o som do bebé como produzido a pouca distancia da glote. Isso é correto porque num bebé de poucos meses a articulação velar dá-se muito próximo da posição, elevada, da glote, mas a interpretação articulatória que os adultos fazem é errada porque o bebé praticamente nem sequer tem ainda uma faringe suficientemente longa para produzir verdadeiras faringais, do ponto de vista articulatório. Assim, se durante os primeiros meses de vida, o bebé mantiver essa posição articulatória, o som que os adultos ouvem vai sendo sucessivamente cada vez mais interpretado como a velar [k] ou [g] que o bebé de facto sempre articulou.
Por agora é tudo. Vamos para o meu fórum de perguntas e respostas para continuarmos a discussão, fazer perguntas ou comentar este tema!
Até breve!
Fernando F. Romeiro disse:
Falar é fácil, dizes tu, mas entender-te é difícil. Mas a figura da ressonância magnética é seguramente tua pois conheço a tua anatomia exterior,